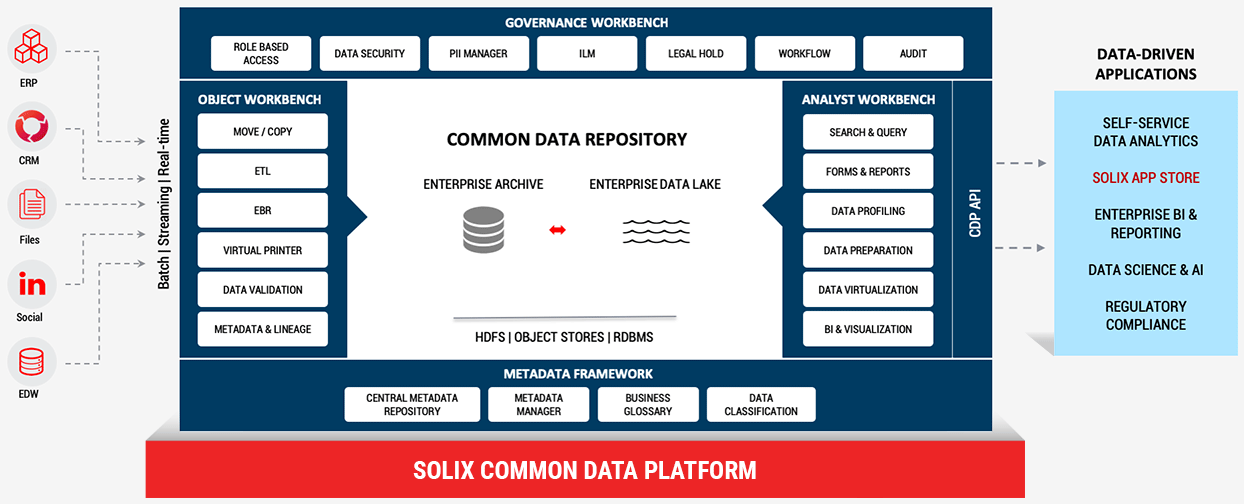
Introducing Solix Common Data Platform
For companies to be data-driven, they have to be able to process the new types of Enterprise data, be it social, IoT, machine data, etc., and make real-time decisions. If companies do not evolve into data-driven organizations, they risk serious business disruption from competitors and startups.
Current Data warehouses are just not ready to be able to handle the volume, velocity, and variety of this new data. New Data Lakes based on Apache Hadoop provide a low-cost answer to the problem of capturing this high volume structured/unstructured data using low-cost infrastructure and open-source software. Data Lake is a storage repository that holds a vast amount of raw data in its native format until it is needed, without imposing a data schema or requirements. When a business question arises, the data lake can be queried for relevant data, and a schema tailored to the question applied to that smaller set of data.
But, there has been significant opposition to this concept. According to Gartner, a Data Lake accepts any data, without oversight or governance. Without descriptive metadata and a mechanism to maintain it, the data lake risks turning into a data swamp. And without metadata, every subsequent use of data means analysts start from scratch. Without appropriate governance measures, Data Lakes can create a ‘data free-for-all’ that exacerbates issues of data quality and data lineage.
It is essential that semi-structured and unstructured data adhere to metadata conventions that have been formally defined by governance principles to ascertain meaning from data. Ensuring that data has uniform metadata standards enables users to understand how data relates to other data—such as how proprietary data from CRM relates to sentiment data, for example. The danger with Data Lakes is that individual end-users are liable to ascribe those attributes that they need within the specific context of their particular business problem or use, which may not follow governance conventions, to the entire data set.
Another risk is security and access control. The security capabilities of central data lake technologies are still immature. Metadata and semantics are essential for ensuring compliance with regulations governing the security, use, and location of specific kinds of data, such as personally identifiable medical information. In theory, independent data marts are no longer necessary as Data Lakes enable the enterprise to distance itself from a silo-based culture while emphasizing sharing and integration. In practice, without Metadata, data marts remain the best way to ensure regulatory compliance and adequate data security.
We believe that with a well-defined business process for data ingestion and with Information Governance, we can address the issues and make Data Lakes Enterprise-ready. Further, if you add the Enterprise Archive to the Data Lake, we can vastly expand the reach of analytics and create an Advanced Analytics Platform. We don’t believe this is a replacement strategy for the data warehouse; in fact, it is more a complement to the existing investment. With that as a goal, we have been working on our new offering – Solix Common Data Platform.
Solix Common Data Platform = Enterprise Archive + Enterprise Data Lake + Information Governance
Here is the comparison on how it differs from a traditional data warehouse and a Data Lake:

Related Posts

Introducing Solix Common Data Platform 3.0

Solix Technologies, Inc. Announces Strong Customer Momentum for SOLIXCloud Enterprise Archiving Solution; Named a Visionary in 2022 Gartner® Magic Quadrant™ for Enterprise Information Archiving
