Unlock AI’s Power with Flawless Data Ingestion
AI data ingestion is the foundational process of collecting, importing, processing, and preparing raw data from diverse sources for consumption and analysis by artificial intelligence and machine learning systems. It is the critical first step in the AI data pipeline, transforming unstructured, semi-structured, and structured data into a clean, unified, and reliable format that fuels accurate AI models and drives intelligent business outcomes. Without a sophisticated ingestion layer, even the most powerful AI algorithms are rendered ineffective, leading to the classic “garbage in, garbage out” dilemma.
What is AI Data Ingestion?
While the term “data ingestion” itself refers to the movement of data from source to target, AI data ingestion is a far more sophisticated and purposeful discipline. It is not merely about transferring bytes; it’s about intelligently curating a high-quality fuel for complex AI engines. In today’s enterprise landscape, valuable data is not confined to neat, traditional databases. It resides in a sprawling digital universe comprising emails, PDFs, images, log files, sensor data from the Internet of Things (IoT), social media feeds, and application data. This data is often messy, inconsistent, and stored in isolated silos.
AI data ingestion addresses this chaos. It involves a series of automated processes that identify, extract, and understand this vast array of data. This goes beyond simple extraction. It includes profiling data to assess its quality, applying initial transformations to standardize formats, and enriching it with metadata to provide context. The ultimate goal is to create a structured, trustworthy, and analytically-ready dataset. This process often follows an ELT (Extract, Load, Transform) model, where raw data is loaded into a scalable repository like a data lakehouse first, and then transformed specifically for the needs of different AI models. This flexibility is crucial for agile AI development. Without this rigorous ingestion process, even the most advanced AI algorithms would struggle with inaccurate, biased, and unreliable outputs.
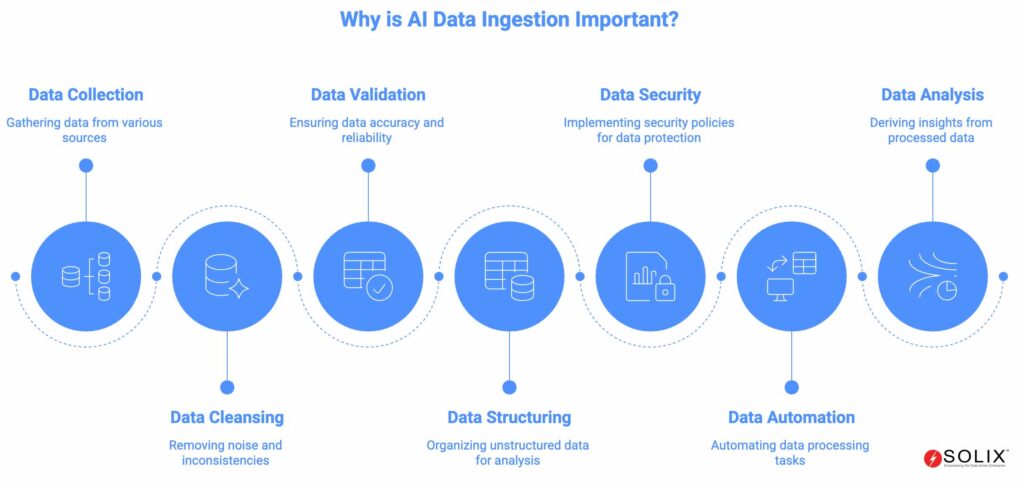
Why is AI Data Ingestion Important?
The efficacy of any AI initiative is directly proportional to the quality and preparedness of the data it consumes. AI data ingestion is not just a technical prerequisite; it is a strategic imperative that unlocks the true potential of artificial intelligence. A mature, automated ingestion pipeline is the backbone of successful AI deployment, delivering foundational benefits across the organization.
- Ensures High-Quality Data for Accurate AI Models: AI and machine learning models are exceptionally sensitive to data quality. A robust ingestion process includes data cleansing, deduplication, and validation, which removes noise and inconsistencies. This results in models that learn from a pristine dataset, dramatically improving their accuracy, reliability, and predictive power. Clean data is the primary defense against biased or flawed AI.
- Accelerates Time-to-Insight: Manual data collection and preparation are slow, error-prone, and cannot scale to meet modern data volumes. Automated AI data ingestion pipelines can process terabytes of data in minutes, continuously feeding fresh information to AI systems. This agility allows businesses to react to market changes in near real-time and derive actionable insights faster than their competitors, creating a significant competitive advantage.
- Enables the Use of Unstructured Data: Over 80% of an organization’s data is unstructured—a massive, untapped reservoir of potential intelligence. Advanced AI data ingestion platforms can parse and structure this data, turning text, images, and videos into quantifiable, analyzable information. This unlocks insights from customer reviews, legal documents, and multimedia content that were previously inaccessible, revealing new patterns and opportunities.
- Lays the Foundation for Automation and Innovation: Reliable data is the lifeblood of automation. From robotic process automation (RPA) to intelligent chatbots and predictive maintenance systems, all rely on a constant stream of clean, well-ingested data. A solid ingestion pipeline is, therefore, the essential first step in building a truly automated and intelligent enterprise capable of self-optimizing processes.
- Improves Data Security and Governance: A centralized and controlled ingestion process allows for the implementation of consistent security policies from the very beginning. Data can be classified, masked, or redacted at the point of ingestion to ensure compliance with regulations like GDPR, CCPA, and HIPAA. This proactive approach minimizes risk and builds a framework of trust around your most valuable data assets.
- Reduces Operational Costs and Complexity: By automating the most labor-intensive part of the data lifecycle, organizations free up valuable data engineering resources. This reduces manual effort, minimizes errors that are costly to rectify downstream, and simplifies the overall data architecture. The result is significant cost savings, improved operational efficiency, and a more focused data team.
Challenges and Best Practices for Businesses
Implementing a robust AI data ingestion strategy is fraught with challenges that can derail even the most well-funded AI projects. Recognizing these hurdles and adhering to established best practices is key to building a successful and scalable data pipeline.
Common Challenges:
- Data Volume and Velocity: The sheer amount of data generated daily can overwhelm traditional infrastructure. Streaming data from IoT devices or financial transactions adds another layer of complexity, requiring systems that can handle constant, high-velocity inflows without bottlenecks.
- Data Variety and Fragmentation: Data exists in countless formats and locations—structured databases, semi-structured JSON/XML, and unstructured documents, emails, and videos. Consolidating these disparate fragments into a coherent whole is a monumental task that often reveals deep-seated data silos within organizations.
- Ensuring Data Quality at Scale: Manually checking data for accuracy, completeness, and consistency is impossible at terabyte or petabyte scale. Ingesting poor-quality data propagates errors through the entire AI pipeline, corrupting models and leading to erroneous business insights.
- Data Security and Compliance Risks: Moving data, especially sensitive personal information, always carries inherent risk. Ingesting data without proper governance can lead to accidental exposure and severe regulatory penalties.
- Scalability and Infrastructure Costs: Building and maintaining a custom ingestion pipeline that can scale elastically with demand requires significant investment in engineering talent and cloud infrastructure, which can become prohibitively expensive if not managed correctly.
Essential Best Practices:
- Profile Data at the Source: Before moving a single byte, analyze the source data to understand its structure, quality, and content. This initial assessment helps identify potential issues early and informs the design of the ingestion pipeline.
- Embrace Automation: Manual processes are the enemy of scale. Automate every possible step of the ingestion workflow—from data extraction and validation to loading and initial transformation. This reduces human error and frees up your team for higher-value tasks.
- Implement Robust Data Governance Early: Do not treat governance as an afterthought. Integrate data classification, privacy policies, and access controls directly into the ingestion process. This “governance by design” approach ensures compliance and security are baked in, not bolted on.
- Design for Scalability and Flexibility: Choose tools and architectures that can scale horizontally to handle increasing data loads. Your ingestion framework should be flexible enough to accommodate new data sources and formats without requiring a complete redesign.
- Prioritize Metadata Management: From the moment data is ingested, capture comprehensive metadata. This includes technical metadata (source, format, size) and business metadata (definitions, owners, sensitivity). Rich metadata is essential for data discovery, lineage tracking, and building trust in your AI outputs.
- Plan for both Batch and Streaming: A modern business needs both. Use batch ingestion for large volumes of historical data and streaming for real-time analytics. Your platform should support both paradigms to serve a wide range of AI use cases.
How Solix Helps Master AI Data Ingestion
Understanding the critical importance of AI data ingestion and its associated challenges is one thing; successfully implementing it at an enterprise scale is another. The challenges of data sprawl, format diversity, and stringent governance requirements can overwhelm traditional data management tools. This is where a purpose-built platform becomes indispensable.
Solix Technologies, as a leader in enterprise data management, provides the foundational infrastructure necessary to master AI data ingestion. The Solix Common Data Platform (CDP) is engineered to serve as the robust, intelligent, and secure data pipeline that modern AI initiatives demand. Our platform doesn’t just move data; it prepares it for intelligence, directly addressing the common challenges businesses face.
Solix CDP offers a unified environment to automate the end-to-end ingestion process. It connects seamlessly to hundreds of data sources—from legacy applications and databases to cloud-native services and IoT streams—using a library of pre-built connectors. This directly tackles the challenge of data variety and fragmentation. Once connected, the platform’s powerful data processing engine profiles, cleanses, and classifies the incoming data, applying business rules to ensure consistency and quality from the very beginning, thus solving the data quality at scale problem.
A key differentiator for Solix is our deep understanding of data governance. The platform is built with a “governance by design” approach. As data is ingested, it is automatically classified and tagged with metadata. This allows for the enforcement of data privacy and security policies at the source, ensuring that sensitive information is protected and compliance is maintained throughout the AI lifecycle. This creates a trusted data foundation, which is non-negotiable for ethical and effective AI, and directly mitigates security and compliance risks.
Furthermore, Solix CDP helps organizations structure their unstructured data lakes into well-managed Data Lakehouses. This modern architecture combines the cost-effectiveness and scalability of a data lake with the management and ACID transactions of a data warehouse, making it the ideal environment for preparing data for AI and machine learning workloads. The platform’s inherent scalability ensures that it grows with your data needs, addressing infrastructure cost and scalability concerns.
By choosing Solix, you are not just selecting a tool; you are partnering with an expert to build a future-proof data foundation. We empower you to transform raw, chaotic data into a curated, high-value asset, ready to power your most ambitious AI projects and drive a competitive advantage. We provide the automated, governed, and scalable pipeline that turns the theoretical benefits of AI into tangible business results.
Learn more about how Solix can streamline your data management with solutions like Enterprise Data Archiving and our approach to the Data Lakehouse.
Frequently Asked Questions (FAQs) about AI Data Ingestion
What is the difference between data ingestion and ETL?
Data ingestion focuses primarily on the “Extract” and “Load” phases, moving data from sources to a target repository like a data lake. ETL (Extract, Transform, Load) involves significant transformation of data before loading it into a structured data warehouse. AI data ingestion often uses an ELT (Extract, Load, Transform) approach, loading raw data first and transforming it later as needed for specific AI models.
What are the common challenges in AI data ingestion?
Key challenges include handling the volume and variety of data (especially unstructured data), ensuring data quality at scale, managing data from siloed sources, maintaining data security and privacy during transfer, and the high cost and complexity of building and maintaining custom ingestion pipelines.
How does AI data ingestion handle unstructured data?
Advanced platforms use techniques like natural language processing (NLP) to understand text, computer vision to analyze images and videos, and speech-to-text for audio. They extract metadata, entities, and relationships from this unstructured content, converting it into a structured or semi-structured format that AI models can process.
Why is data quality so critical in AI data ingestion?
AI and ML models learn patterns from the data they are fed. If the ingested data is incomplete, inaccurate, or biased, the model’s outputs and predictions will be similarly flawed. This is known as “garbage in, garbage out.” High-quality ingestion is the primary defense against this, ensuring model accuracy and reliability.
What is the role of a data lakehouse in AI data ingestion?
A data lakehouse is a central repository that combines the scalability and flexibility of a data lake with the management and transaction capabilities of a data warehouse. It is an ideal target for AI data ingestion pipelines because it allows you to store vast amounts of raw, unstructured data while also providing the structure needed for efficient AI model training and analytics.
How can automated AI data ingestion save costs?
Automation drastically reduces the manual labor required for data collection and preparation. It minimizes errors that lead to rework and faulty business decisions, optimizes infrastructure usage, and allows data teams to focus on higher-value tasks like analysis and model building, rather than data wrangling. This leads to direct labor savings and indirect cost savings from better decisions.
What is real-time AI data ingestion?
Real-time ingestion, also known as streaming ingestion, involves continuously collecting and processing data the moment it is generated. This is essential for AI use cases like fraud detection, dynamic pricing, and IoT monitoring, where insights are required instantly to trigger actions and responses.
How does Solix ensure data security during the ingestion process?
The Solix Common Data Platform incorporates security features like encryption in transit and at rest, fine-grained access controls, and data masking. Its built-in data classification automatically identifies and protects sensitive information as it is ingested, ensuring compliance with data privacy regulations from the very start of the data lifecycle.




