
Executive Summary
Enterprise data preservation has moved far beyond cost savings. Three forces—cloud migration, surging M&A activity, and AI’s demand for governed data—have made it a strategic imperative. This post examines how application retirement now includes cybersecurity urgency, how M&A drives rapid data consolidation requirements, and how a third use case has emerged: AI enablement, where preserved data becomes the training ground for enterprise AI models and digital workers. It also explores how AI-powered access through the Application Knowledge Graph has transformed preserved data from static archives into living, queryable assets.
In 2020, we published a white paper that made a simple case: retiring inactive legacy applications saves money. License fees, hosting costs, maintenance labor—it all adds up. A single enterprise application can cost tens of thousands to well over six figures per year just to keep the lights on. Multiply that across hundreds of dormant systems and you’re looking at millions in recoverable spend.
That ROI story hasn’t changed. But the world around it has—dramatically. Three forces have converged to make enterprise data preservation not just a cost play, but a strategic imperative.
Three Forces Reshaping Data Preservation
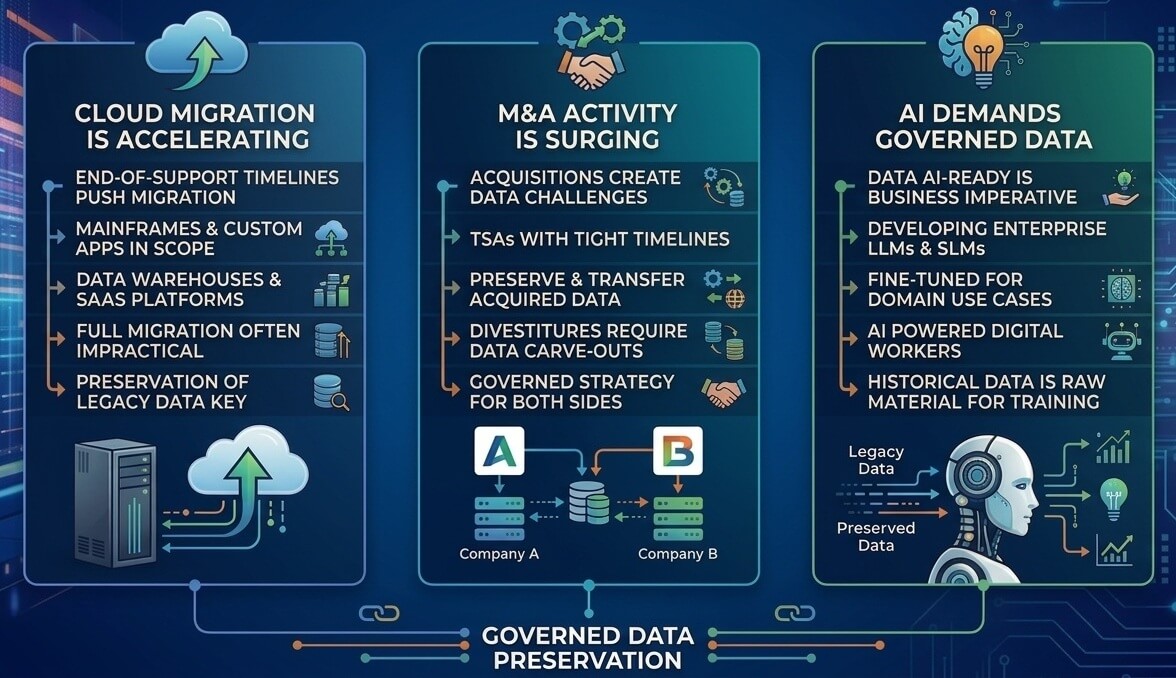
Cloud migration is accelerating. Major vendors are pushing cloud migration with end-of-support timelines. But the scope extends beyond ERP: mainframes, custom applications, data warehouses, SaaS platforms, and email repositories all hold data that must be preserved and remain accessible—and full migration is neither practical nor cost-effective.
M&A activity is surging. Every acquisition brings a new data preservation challenge. Purchase agreements include Transition Services Agreements (TSAs) with tight timelines for preserving and transferring the acquired company’s data. And it’s not just the buy side—divestitures and spin-offs require carving out specific data sets from entangled enterprise systems. Both sides of the deal need a governed data preservation strategy.
AI demands governed data. The concept of “making your data AI-ready” has moved from aspiration to business imperative. And the scope of AI readiness is expanding: enterprises are no longer just consuming third-party AI services—they are increasingly developing their own large language models (LLMs) and small language models (SLMs) fine-tuned for domain-specific use cases, and deploying AI-powered digital workers that automate complex business processes. The historical data locked inside legacy and acquired applications is the raw material these models need for training, fine-tuning, and grounding. Preserved data is no longer just a compliance obligation; it’s fuel for intelligent analysis, model development, and competitive differentiation.
The Security Angle No One Talks About
Here’s what’s changed most since 2020: legacy systems aren’t just expensive—they’re dangerous. Tens of thousands of new CVEs were disclosed in just the first half of 2025. Threat actors weaponize new vulnerabilities within days, while organizations take an average of months to deploy patches. For legacy systems with no vendor support, that gap is infinite.
This isn’t theoretical. In 2025, a critical zero-day in Oracle E-Business Suite (near-maximum CVSS severity) was actively exploited in ransomware campaigns. A separate zero-day in SAP NetWeaver gave attackers full system compromise through a component that was “forgotten” and unmonitored. These are exactly the kinds of systems sitting in data centers across the enterprise.
Attackers now leverage AI to find and exploit vulnerabilities faster than ever. Every legacy system decommissioned is one less entry point for ransomware, data exfiltration, and supply chain attacks.
Decommissioning these systems isn’t just IT hygiene, it’s attack surface reduction, and it’s becoming a board-level conversation.
AI Changes Everything About Data Access
The biggest barrier to application retirement has always been end-user resistance. Ask users how they want to access their archived data, and the answer is predictable: “Leave my application alone.”
In 2020, the best we could offer was Enterprise Business Records paired with text search—a major improvement over recreating legacy reports, but still requiring users to learn new search conventions. In 2026, the answer is fundamentally different. With Solix Data Ask, users can simply ask a question in plain English “Show me all AP invoices over $50,000 from Q4 2023” and get an accurate, governed answer in seconds.
The technology behind this is the Application Knowledge Graph—a semantic layer that encodes deep, application-specific knowledge: table relationships, business rules, naming conventions, and proven query patterns. This matters because generic AI tools fail on real enterprise data. Academic benchmarks show high accuracy on simple schemas, but generic tools fail dramatically on real enterprise schemas with thousands of tables. The Knowledge Graph bridges that gap.
Data Ask is voice-enabled—users can ask questions by speaking and receive spoken answers. When a question is ambiguous, Data Ask asks clarifying questions before executing; it never guesses. Query results are automatically visualized as charts with business-friendly column names.
Every answer is governed by enterprise-grade safeguards: anti-hallucination controls validate results before delivery, confidence scores tell users when further validation may be warranted, and a full audit trail logs every query for compliance.
For unstructured data—documents, contracts, emails—semantic search powered by retrieval-augmented generation (RAG) synthesizes answers across the full document corpus with citations to source materials. Together, these capabilities transform preserved data from a compliance archive into a living, queryable asset.
Data Ask unifies these capabilities through a three-engine architecture. An AI-powered Conversation Router classifies every question in real time and sends it to the right engine—structured data, intelligent search, or both simultaneously. A single question can fire both engines in parallel, delivering a synthesized response with data tables and document citations in one answer.
AI Enablement: The Third Use Case
As AI adoption matures, a critical strategic dimension is emerging. Organizations are no longer content to rely solely on general-purpose AI models—they are building their own. A financial services firm trains models on its specific accounting conventions. A manufacturer encodes decades of production process knowledge. A pharmaceutical company builds models on proprietary clinical trial data. In each case, the quality and depth of the training data is the decisive competitive advantage.
This extends to digital workers—autonomous AI agents that observe, plan, and execute complex business processes with minimal human intervention. Digital workers are being deployed to automate audit preparation, accelerate financial close, manage procurement workflows, and handle compliance monitoring. These agents are only as capable as the data they are trained on and grounded in. An organization’s historical data—decades of transactions, decisions, exceptions, and outcomes captured in legacy systems—represents the institutional memory that makes digital workers effective.
This reframes the entire value proposition of data preservation. The data being migrated out of retired applications and acquired companies is not merely being archived—it is being assembled into a strategic training data reservoir. Data that has been classified, validated, and semantically mapped through a Knowledge Graph is dramatically more valuable for model training than raw database extracts.
And the AI enablement story doesn’t stop at preserved data. The same Knowledge Graph technology that makes archived data intelligently accessible can be applied to live production systems—enabling real-time, natural-language analytics against active applications. Imagine combining both dimensions: a Knowledge Graph built for a production ERP gives business users real-time operational intelligence, while the same Knowledge Graph applied to preserved historical data enables deep longitudinal analysis. The combination of real-time and historical insight, powered by a unified Knowledge Graph infrastructure, creates an AI-enabled analytics capability that no traditional BI platform can match.
Navigating Data Sovereignty and International AI Policy
Compounding the strategic picture is data sovereignty. The EU AI Act, India’s AI Governance Guidelines, and a patchwork of U.S. state-level AI legislation all impose distinct requirements around data governance, bias mitigation, transparency, and human oversight. For multinational organizations, historical data from retired applications and acquired companies may span dozens of countries, each with different rules about data residency, AI training data usage, and cross-border transfer.
Organizations developing proprietary AI models must understand not only what data they have, but where it resides and which jurisdictions govern its use. A flexible deployment architecture—one that enables centralized governance with decentralized operations—is essential for maintaining compliance while unlocking the full value of preserved data across borders.
The Preservation System of Record
Supporting all of this is what we call the Preservation Zone—a dedicated, governed repository within the Solix data platform designed to be the authoritative home for all preserved enterprise data. Whether the data comes from a retired application, an acquired company, or a divested business unit, it lands in a single, consolidated environment with comprehensive ingestion, automated validation, intelligent classification, data quality assurance, retention management, and role-based security.
Data quality deserves special emphasis. Before any preserved data is AI-enabled, it must be validated, profiled, and remediated to earn the trust required for AI-powered analytics. You can’t build reliable insights on unreliable data—and that’s especially true for acquired data, where quality and completeness can’t be assumed.
The Bottom Line
The business case for enterprise data preservation has never been stronger—or more multidimensional. Cost savings from application retirement remain compelling. M&A data management is now a primary driver. Cybersecurity demands that we reduce the legacy attack surface. And AI enablement—turning preserved and live data into fuel for enterprise models, digital workers, and real-time analytics—has emerged as a use case in its own right.
But the real story in 2026 is that preserved data is no longer a burden to be maintained at minimum cost—it is a strategic asset that serves as the foundation for enterprise AI. As organizations develop their own language models, deploy digital workers, and navigate an increasingly complex web of international AI and data sovereignty regulations, the decisions they make today about what data to preserve, how to govern it, and how to maintain its semantic context will directly determine their AI capabilities for years to come.
Organizations that approach data preservation with this long-term strategic perspective—treating every data set as a potential input to future AI models, ensuring compliance across jurisdictions, and building the governed, semantically enriched data foundations that intelligent systems demand—will be the ones best positioned to lead in the AI era.
Preserved data is no longer a burden—it is fuel for intelligent analysis, discovery, and decision-making.
To learn more, read our full white paper: Enterprise Data Preservation: From Application Retirement to AI-Ready Data Assets, available at solix.com.
Mark Lee
Chief Product Officer
DISCLAIMER: THE CONTENT, VIEWS, AND OPINIONS EXPRESSED IN THIS BLOG ARE SOLELY THOSE OF THE AUTHOR(S) AND DO NOT REFLECT THE OFFICIAL POLICY OR POSITION OF SOLIX TECHNOLOGIES, INC., ITS AFFILIATES, OR PARTNERS. THIS BLOG IS OPERATED INDEPENDENTLY AND IS NOT REVIEWED OR ENDORSED BY SOLIX TECHNOLOGIES, INC. IN AN OFFICIAL CAPACITY. ALL THIRD-PARTY TRADEMARKS, LOGOS, AND COPYRIGHTED MATERIALS REFERENCED HEREIN ARE THE PROPERTY OF THEIR RESPECTIVE OWNERS. ANY USE IS STRICTLY FOR IDENTIFICATION, COMMENTARY, OR EDUCATIONAL PURPOSES UNDER THE DOCTRINE OF FAIR USE (U.S. COPYRIGHT ACT § 107 AND INTERNATIONAL EQUIVALENTS). NO SPONSORSHIP, ENDORSEMENT, OR AFFILIATION WITH SOLIX TECHNOLOGIES, INC. IS IMPLIED. CONTENT IS PROVIDED "AS-IS" WITHOUT WARRANTIES OF ACCURACY, COMPLETENESS, OR FITNESS FOR ANY PURPOSE. SOLIX TECHNOLOGIES, INC. DISCLAIMS ALL LIABILITY FOR ACTIONS TAKEN BASED ON THIS MATERIAL. READERS ASSUME FULL RESPONSIBILITY FOR THEIR USE OF THIS INFORMATION. SOLIX RESPECTS INTELLECTUAL PROPERTY RIGHTS. TO SUBMIT A DMCA TAKEDOWN REQUEST, EMAIL INFO@SOLIX.COM WITH: (1) IDENTIFICATION OF THE WORK, (2) THE INFRINGING MATERIAL’S URL, (3) YOUR CONTACT DETAILS, AND (4) A STATEMENT OF GOOD FAITH. VALID CLAIMS WILL RECEIVE PROMPT ATTENTION. BY ACCESSING THIS BLOG, YOU AGREE TO THIS DISCLAIMER AND OUR TERMS OF USE. THIS AGREEMENT IS GOVERNED BY THE LAWS OF CALIFORNIA.
What you can do with Solix

Enter to win a $100 Amex Gift Card
-
 White Paper
White PaperEnterprise Information Architecture for Gen AI and Machine Learning
Download White Paper -

-

-
