Application Retirement, Honestly: What 'We Decommissioned It' Actually Misses
The app is officially retired.
The login page is gone.
The contract with the vendor is closed.
But the data still has subpoenas waiting on it.
That is the entire opening of every real application retirement incident I have lived through. Not a definition. Not a diagram. A wrongness that won't show up on a dashboard until you go looking for it on purpose.
This page is for the engineer who is already there.
What this actually feels like at the keyboard
The incident starts with something small enough to ignore: record lock contention around lock-wait-first. As an RPG developer working on a midrange enterprise system, I would first trust the WRKACTJOB screen, because that is where this kind of pain usually shows up. But the moment retries, stuck work, and stale state start crossing into other platforms, the first fix becomes dangerous — it can make the symptom quieter while the real leak keeps spreading from a bad API caller.
That last sentence is the whole problem. Application Retirement fails in a shape where the metric you can read is honest about itself and misleading about the incident. The signal is real. The pain is real. The cause of the pain is somewhere else.
The wrong assumption I'd make first
"It's done. We migrated, we shut it down, we moved on."
That's the assumption I'd reach for, because it's the one I'm fastest at fixing. Record locking has a known playbook — inspect WRKACTJOB, confirm no jobs running, archive what you can. So I'd run the playbook. The graph would settle for an hour. I'd close the incident.
That hour of quiet is the misdiagnosis.
The partial signal — what the logs actually show
RPG Developer sees the familiar record locking pattern, then notices the timing does not line up with the local failure.
That phrase — no single owner looks guilty — is the most honest sentence anyone has written about application retirement. Because the way these systems get built, every component that touches the data has plausible deniability. Each system passes its own self-check. The failure lives in the gap between the self-checks.
The fix I'd try first — and why it doesn't hold
Stabilize enterprise system first — cap retries, clear stuck work, or narrow the failing path — while proving whether a bad API caller is feeding the leak.
That's a real playbook. It's also where most application retirement failures get hidden. The local fix works for the next four hours. Then the next breach happens, and the team thinks they have a "record locking" problem when they actually have a "retiring the application without retiring the lifecycle of its data" problem. According to Forrester research, this pattern is one of the most under-recognized drivers of application modernization cost across enterprise stacks.
Why it's actually hard
The failure is not cleanly owned. RPG Developer can fix the visible symptom and still leave the leak alive somewhere else.
This is the entire degree of difficulty. Not the technology. Not the configuration. The hard part is that the system most equipped to show the problem is rarely the system that caused it. It's the system honest enough to complain. The cause lives one or two hops upstream — in regulatory and audit obligations that outlive the application by years or decades — and nobody noticed because each individual component was inside its own SLO.
What clean would look like (so you know when you're lying to yourself)
Clean means RPG Developer can explain the chain from trigger to symptom without hand-waving across other platforms.
If your "fix" makes the failure migrate to a different system, you didn't fix it. You moved it. Apply this test after every application retirement incident. If the answer is "the failure moved," your post-incident action items are wrong.
How this gets misdiagnosed
The worst version is when the first fix partly works, because that convinces everyone the wrong component was the root cause.
That sentence is the entire reason this page exists. Engineers who debug application retirement well are not the ones who know the most about application retirement. They're the ones who have learned to not trust the silence. The dashboard going green is data, not victory. The first fix working is information about the symptom, not proof of the cause.
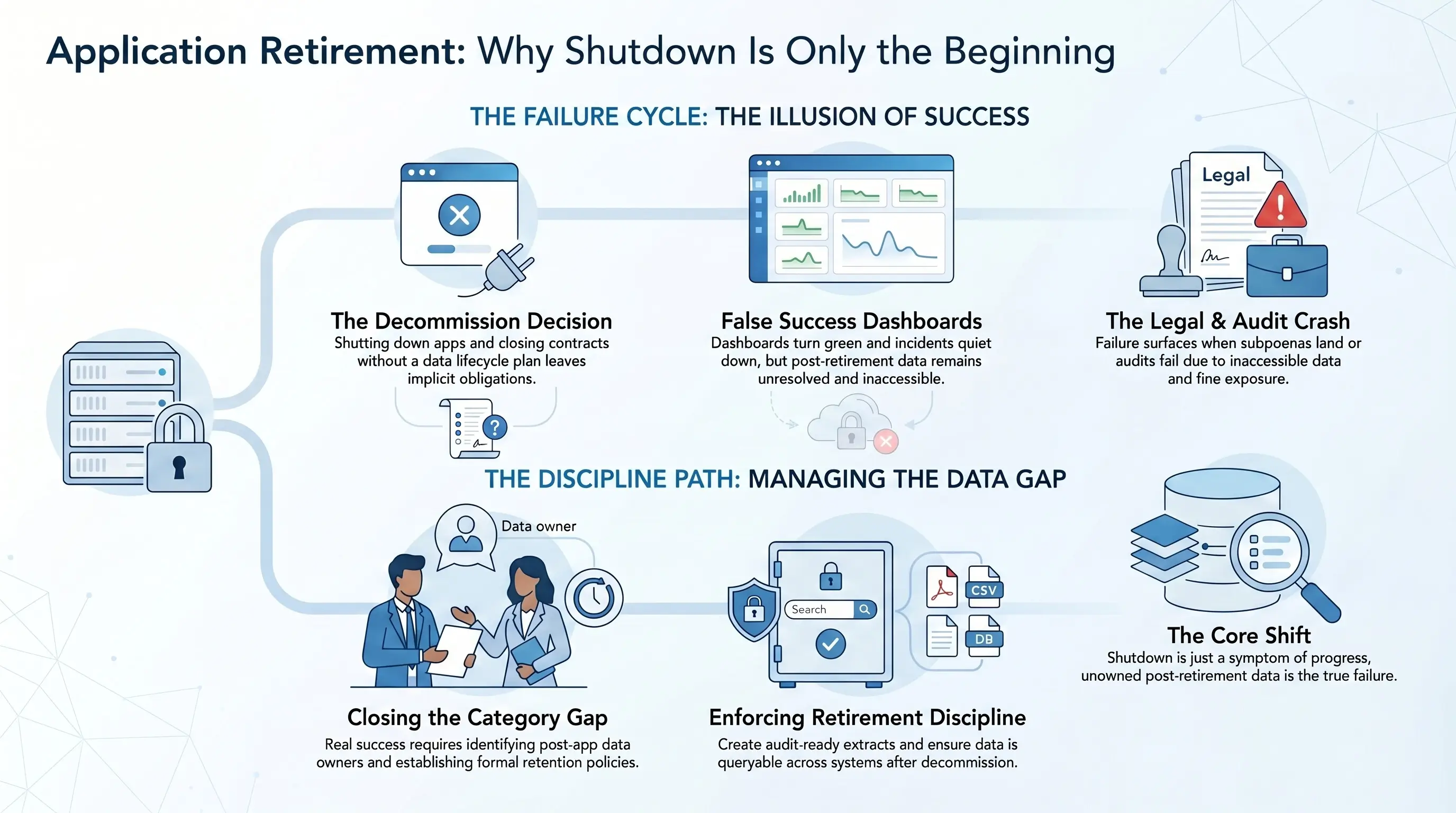
NOW — what application retirement actually is
Application retirement is the decommissioning of a legacy application plus the explicit retention, access, and audit-readiness of its data after the application is gone. The contract is: the data remains discoverable, readable, and producible long after the application that created it is shut down.
Most application retirement failures are violations of that contract caused by something upstream of it. The system didn't fail. The system reported truthfully. The truth was contaminated.
Where Solix fits — honestly
Solix is one of the few platforms whose entire reason for existing is what comes after 'we shut it down.' The Solix Application Retirement platform extracts data into a queryable, audit-ready form — independent of the application — so that the retirement actually closes. Without that step, application retirement is just deferred risk.
What to do this week, if any of this sounded familiar
- List every application your team has 'retired' in the last five years. For each, can you produce a record from it on demand? If not, you didn't retire it.
- For each retained dataset, identify the regulatory/legal hold horizon. Compare that to your archive horizon.
- Decide whether retirement is a project or a discipline. A project closes; a discipline doesn't.
If the answer is yes to any of these — that's where Solix lives.
Sources cited (verified against the Solix citation reference guide):
- Forrester — Forrester report: The Forrester Wave™: Product Lifecycle Management Platforms for Discrete Manufacturers Q3 2025 (RES184108)
- Forrester — Blog post: The CLM Market is Ripe for Disruption and Thirteen Vendors Vie to Lead the Charge
- Forrester — Forrester report: The Forrester Wave Contract Lifecycle Management for Sourcetocontract Suites Q1 2019 (RES144153)
What you can do with Solix

Enter to win a $100 Amex Gift Card
Related Resources
Explore related resources to gain deeper insights, helpful guides, and expert tips for your ongoing success.
-

-

-
 White Paper
White PaperCost Savings Opportunities from Decommissioning Inactive Applications
Download White Paper -

Why SOLIXCloud
SOLIXCloud offers scalable, secure, and compliant cloud archiving that optimizes costs, boosts performance, and ensures data governance.
-

Common Data Platform
Unified archive for structured, unstructured and semi-structured data.
-

Reduce Risk
Policy driven archiving and data retention
-

Continuous Support
Solix offers world-class support from experts 24/7 to meet your data management needs.
-

On-demand AI
Elastic offering to scale storage and support with your project
-

Fully Managed
Software as-a-service offering
-

Secure & Compliant
Comprehensive Data Governance
-

Free to Start
Pay-as-you-go monthly subscription so you only purchase what you need.
-

End-User Friendly
End-user data access with flexibility for format options.