What is Change Data Capture (CDC)?
Change Data Capture (CDC) refers to the process of identifying and capturing changes made to data in a database over a specific period, in real-time or near-real-time. Instead of taking periodic snapshots of the entire database, CDC captures the delta – the specific changes that occur – keeping downstream systems constantly updated.
Why use CDC?
Imagine your enterprise relies on customer data in multiple systems: a CRM for managing interactions, a data warehouse for analysis, and a marketing platform for targeted campaigns. Without CDC, any change in a customer’s address, phone number, or purchase history might take hours or even days to reflect across all systems. This data lag can create inconsistencies, hindering accurate reporting, personalized marketing, and efficient customer service.
Key benefits of CDC
- Real-time data synchronization: Ensures all systems have the latest information, enabling faster decision-making and reactive workflows.
- Enhanced data accuracy and consistency: Reduces data discrepancies and improves data quality across your organization.
- Streamlined data integration: Simplifies moving data between various systems, accelerating analytics and reporting.
- Reduced workload and resource utilization: Eliminates the need for full data refreshes, saving time and infrastructure costs.
When to use CDC?
CDC is particularly valuable in scenarios where:
- Data changes frequently: Customer information, inventory levels, financial transactions, or sensor readings benefit from immediate updates.
- Downstream systems rely on real-time data: E-commerce platforms, personalized recommendation engines, and fraud detection systems need instantaneous data feeds.
- Data consistency is critical: Ensuring all systems operate on the same accurate data is crucial for financial reporting, regulatory compliance, and customer trust.
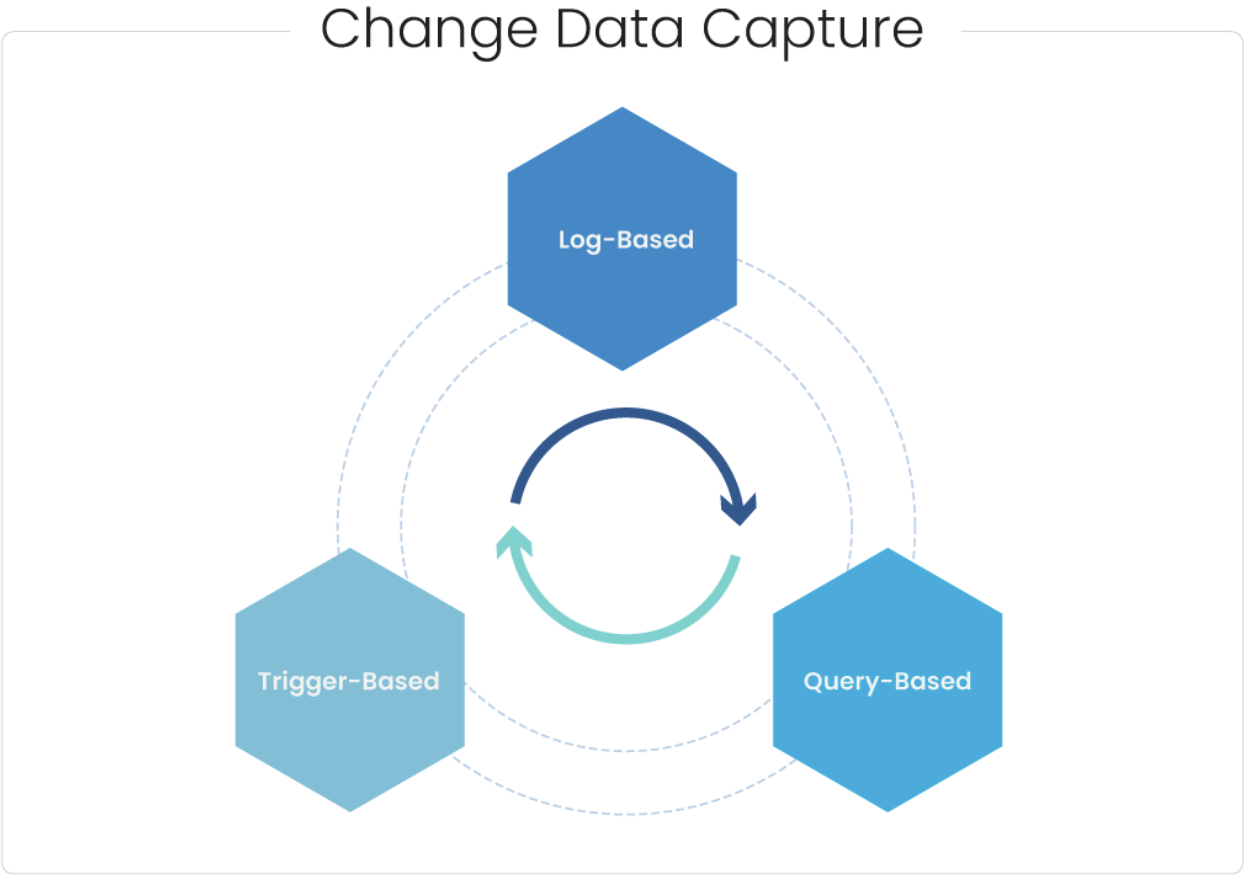
Types of CDC Approaches
- Log-based CDC: Monitors database logs to identify data modifications.
- Trigger-based CDC: Leverages database triggers to capture changes as they occur.
- Query-based CDC: Executes specific queries at intervals to identify changes.
CDC acts as a data bridge, keeping your systems aligned and your information flowing smoothly. Whether you’re running a dynamic restaurant or a data-driven enterprise, CDC ensures everyone is working on the latest data for optimal results.
FAQs
Is CDC secure?
CDC can be secure, but it’s important to implement proper security measures. This includes controlling access to the captured data changes and ensuring they are encrypted in transit and at rest.
Does CDC impact database performance?
The impact of CDC on database performance can vary depending on the implementation method and the volume of data changes. Log-based CDC can have a minimal impact, while trigger-based CDC might have a more noticeable effect. It’s crucial to properly configure CDC to minimize performance overhead.
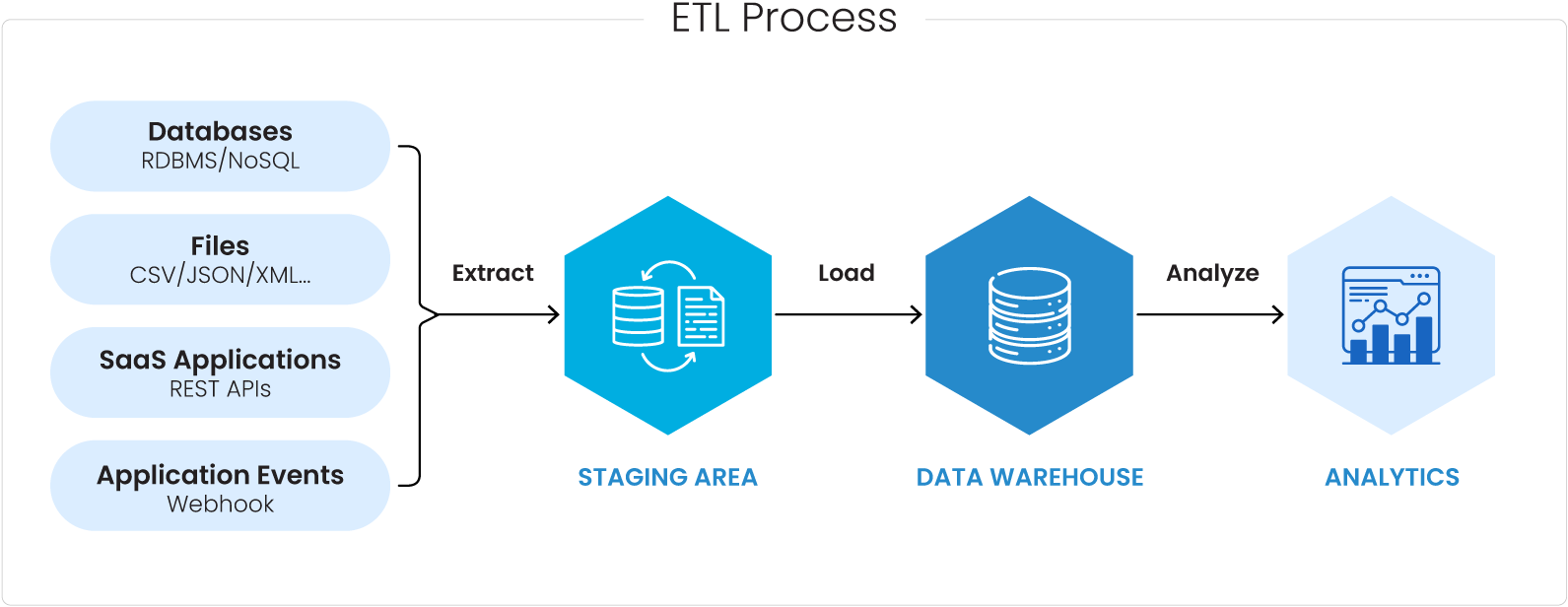
How does CDC differ from traditional ETL (Extract, Transform, Load)?
Traditional ETL typically extracts data in full batches at regular intervals. CDC, on the other hand, focuses on capturing only the changes that occur in the data, providing a more real-time and efficient approach to data integration.
What are some limitations of CDC?
CDC might not be suitable for all scenarios. For instance, if data changes are very complex or the source database doesn’t support CDC mechanisms, alternative approaches like full data extracts might be necessary.