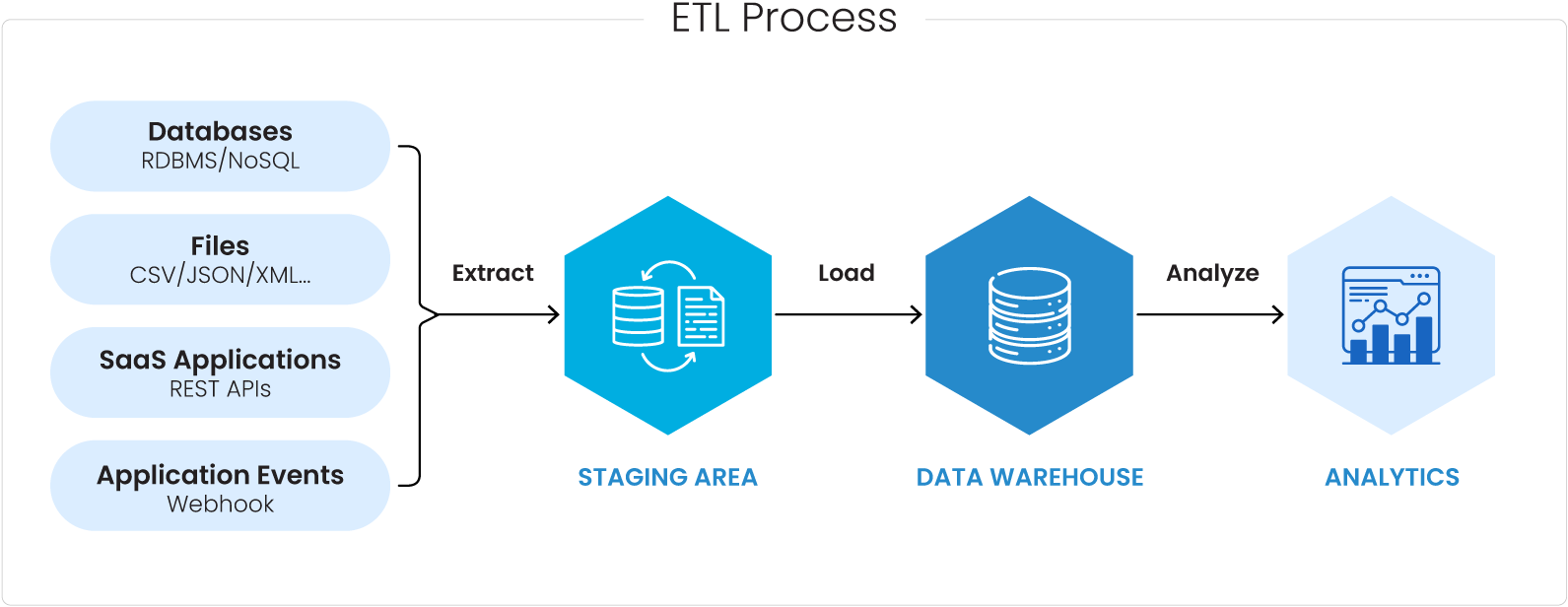
What are Bulk Inserts?
Bulk inserts refer to a database operation that involves inserting many records into a database table in a single operation, rather than inserting each record individually. This method is commonly used to improve performance and efficiency when dealing with substantial data.
How Bulk Inserts Work
The specific implementation of bulk inserts varies depending on the DBMS. However, the general concept involves:
- Data Preparation: The data is typically formatted in a specific way, often a flat file like CSV or a proprietary format.
- Bulk Insert Command: A special command provided by the DBMS is used to initiate the bulk insert operation. This command specifies the target table and the location of the data source.
- Data Loading: The DBMS engine efficiently loads the data from the source into the table, optimizing the process for speed and efficiency.
Methods of Bulk Insert
- SQL Statements: Many database management systems (DBMS) provide specific SQL commands for bulk inserts for multiple rows in SQL Server and MySQL.
- Utility Tools: Tools like bcp (Bulk Copy Program) in SQL Server, COPY command in PostgreSQL, and LOAD DATA INFILE in MySQL are designed for bulk data loading.
- APIs and Libraries: Programming languages often provide APIs or libraries (like JDBC for Java, psycopg2 for Python with PostgreSQL) that support bulk insert operations.
Use Cases for Bulk Insert
- Data Migration: Transferring large datasets from one system to another.
- Data Warehousing: Loading large volumes of data into a data warehouse for analysis.
- ETL Processes: Extract, Transform, Load (ETL) workflows where data from various sources is consolidated into a single database.
Benefits of Bulk Inserts
- Improved Performance: Bulk inserts significantly reduce the overhead associated with individual INSERT statements. This can lead to substantial performance gains when dealing with large datasets.
- Reduced Server Load: By grouping multiple inserts into a single operation, bulk inserts minimize the number of round trips between the application and the database server, reducing the overall load.
- Faster Data Loading: Bulk inserts can significantly speed up the process of importing data from external sources like CSV files.
Best Practices with Bulk Inserts
- Batch Size Management: Adjusting the batch size to optimize performance and avoid memory issues.
- Error Handling: Implementing robust error handling to manage potential failures during the bulk insert process.
- Index Management: Disabling indexes during bulk inserts can speed up the operation, but indexes should be rebuilt afterward to maintain query performance.
FAQ
How can I handle errors during a bulk insert operation?
Implement robust error handling by using try-catch blocks in your database scripts or application code. You can also log errors to an error table or file for further analysis. For example, some DBMS allow you to skip faulty rows or redirect them to an error table during a bulk insert operation.
Is it necessary to disable indexes before performing a bulk insert?
Disabling indexes before a bulk insert can improve the speed of the operation because the database does not have to update the indexes for each inserted row. However, it is essential to rebuild the indexes afterward to maintain query performance. This approach is particularly useful when inserting a large volume of data.
What batch size should I use for a bulk insert?
The optimal batch size for a bulk insert depends on various factors, including the available memory, the specific DBMS, and the nature of the data being inserted. It’s often recommended to experiment with different batch sizes to find the best balance between performance and resource usage. In general, larger batches reduce the overhead of multiple transactions but may consume more memory.