What is VCDPA?
The Virginia Consumer Data Protection Act 2021 (VCDPA) is a regulation giving Virginia residents control over their data, like the right to delete, access, and rectify personal information collected by certain businesses. It sets forth obligations for businesses regarding consumer data, with exceptions for HIPAA and FERPA-regulated information. Virginia is the second state after California to implement comprehensive data privacy legislation.
Overview of VCDPA
- Law: Virginia Consumer Data Protection Act
- Region: Virginia
- Signed Date: 02-03-2021
- Effective Date: 01-01-2023
- Industry: All industries that do business in Virginia
Personal Data Under the VCDPA
The Virginia Consumer Data Protection Act (VCDPA) defines “personal data” comprehensively, similar to other consumer privacy laws like the California Consumer Privacy Act (CCPA). Here’s a breakdown of the type of data typically covered by VCDPA.
- Basic Identifiers: Basic information like name, address, phone number, email address, IP address, or unique online identifiers (cookies, device IDs).
- Demographic Data: Date of birth, gender, marital status, and information about dependents.
- Commercial Information: Purchase history, browsing behavior linked to an individual, and loyalty program data.
- Geolocation Data: Information about an individual’s physical location, such as GPS coordinates, if precise enough to identify a specific location.
- Sensory Data: Voice recordings, fingerprints, or other biometric data used for identification purposes.
- Internet Activity Data: Browsing history, search queries, and information about a consumer’s interactions with a website or online service.
Key Components
VCDPA establishes guidelines for collecting, using, and sharing personal data by Virginia businesses. Key components include definitions of personal data, requirements for data protection assessments, mandates for data processing limitations like data minimization, purpose limitation, data security measures, and provisions for consumer rights regarding their personal information like rights to access, correct, delete, portability, and opt-out of data sale and targeted advertising.
Who Needs to Comply?
The VCDPA applies to any business that falls under the following criteria:
- Conduct business in Virginia or target products/services to Virginia residents. This includes online and offline businesses, regardless of physical location.
- Control or process personal data of at least 100,000 Virginia residents during a calendar year: This threshold applies to the total number of Virginia residents whose data is processed, even if it’s not the core business activity.
- Control or process personal data of at least 25,000 Virginia residents and derive over 50% of gross revenue from selling personal data: This includes situations where businesses primarily deal with smaller datasets but rely heavily on data sales for income.
Exceptions
- Non-profit organizations, certain financial institutions, healthcare providers, entities, or data subject to Title V of the Gramm-Leach-Bliley Act (GLBA), which largely regulates banks, other financial institutions, and government agencies, are exempt from the VCDPA.
- Deidentified data (data where all identifying information has been removed) may be exempt under specific conditions.
- The exemption also includes entities or business associates governed by HIPAA’s privacy, security, and breach notification rules;
Noncompliance Fines
- Per violation: Up to $7,500 per violation. This means individual instances of non-compliance, such as failing to provide access to data upon request or neglecting to implement reasonable security measures, can incur hefty fines.
- Continuing violations: An additional $750 per day for each day of a continuing violation. This can quickly escalate the financial impact of non-adherence, especially for persistent issues.
- Maximum limit: The total penalty for any violation cannot exceed $2.5 million.
Compliance Authority
The Virginia Attorney General (AG) is solely responsible for enforcing the VCDPA. This means the AG’s office can investigate potential violations, issue warnings and directives to non-compliant businesses, and seek injunctions to halt illegal data practices.
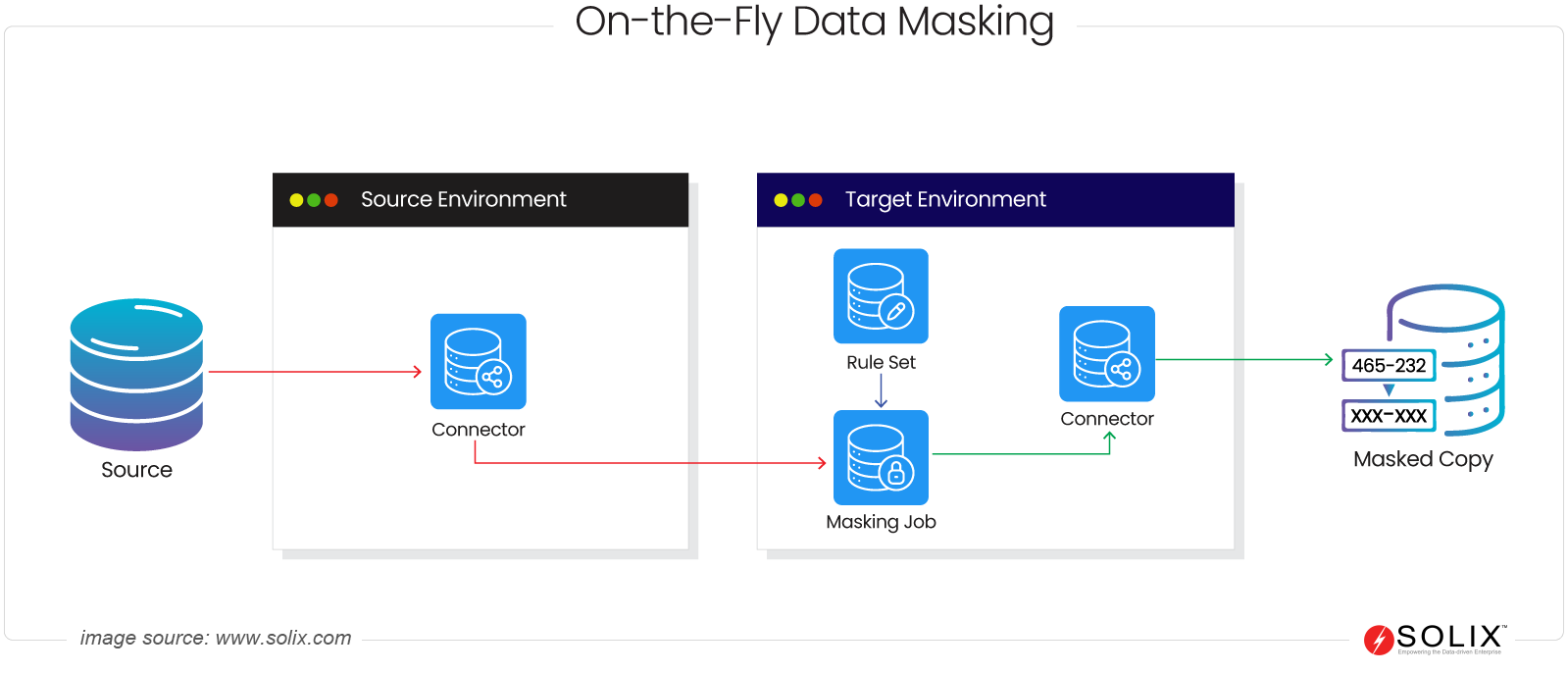
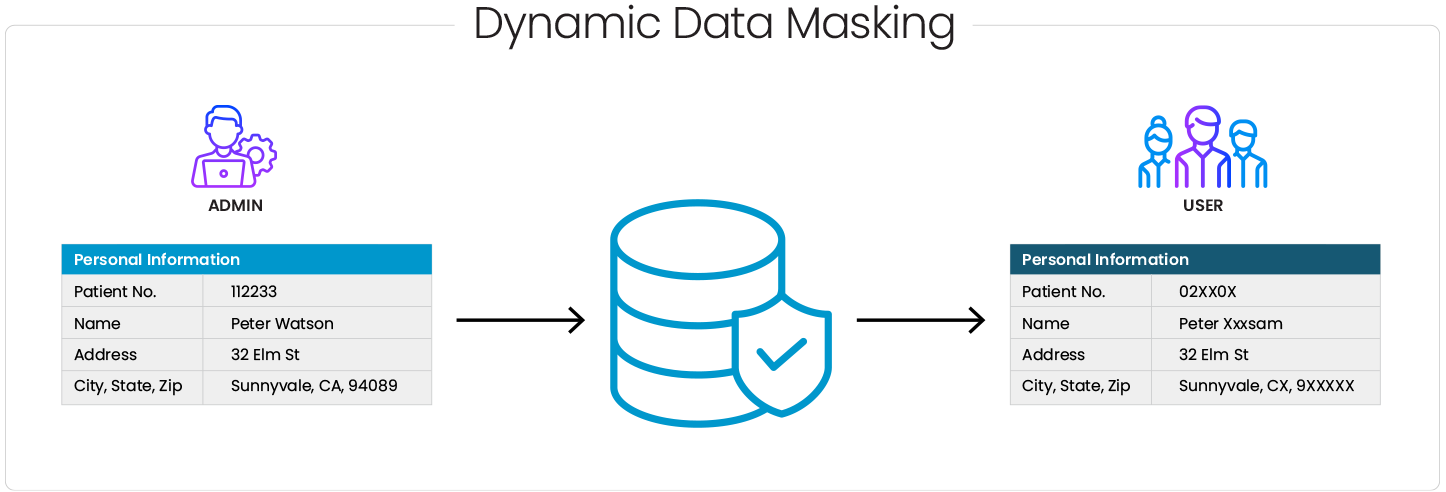
In conclusion, the Virginia Consumer Data Protection Act (VCDPA) represents a significant step towards enhancing consumer data privacy rights and imposing obligations on businesses to protect personal information. Companies can mitigate compliance risks and build trust with their customers by understanding the critical components of VCDPA, respecting consumer rights, and implementing effective data security solutions such as data masking.
FAQ
What is the Virginia Consumer Data Protection Act (VCDPA), and to whom does it apply?
VCDPA is a state-level privacy law in Virginia, USA that protects consumer data. It applies to businesses that control or process the personal data of Virginia residents who meet certain criteria, regardless of their physical location.
What are the critical rights granted to consumers under the VCDPA?
The VCDPA grants consumers rights such as the right to access their data, correct inaccuracies, delete data under certain circumstances, and opt out of the sale of their data. These rights empower consumers to have more control over their personal information.
How does the VCDPA compare to other privacy laws, such as the GDPR or CCPA?
While the VCDPA shares similarities with the GDPR and CCPA in terms of its focus on consumer rights and data protection, it also has unique provisions and requirements tailored to the Virginia legal landscape and business environment.