What is IDPC?
The Italian Data Protection Code, IDPC (Legislative Decree No. 196 of 2003), also known as the Privacy Code, safeguards the processing of personal data in Italy. It establishes data collection, use, storage, and disclosure principles and grants individuals the right to control their information. The GDPR became directly applicable in all EU member states, including Italy, in May 2018. However, Italy passed a decree to harmonize the IDPC with the GDPR.
Overview of IDPC
- Law: Italian Data Protection Code
- Region: Italy
- Signed On: 30-06-2003
- Effective Date: 01-01-2004
- Industry: All industries that do business with Italian residents
Personal Data Under the IDPC
The Code defines personal data broadly, encompassing any information relating to an identified or identifiable natural person. Here’s a breakdown of what the Code considers personal data:
- Direct identifiers: This includes information that can directly identify an individual, such as name, identification number, address, phone number, and email address.
- Indirect identifiers: Examples include location data (GPS coordinates, IP address), online identifiers (cookies, usernames), and physical, physiological, genetic, mental, economic, cultural, or social identity specifics.
The Code offers additional protection for specific categories of personal data deemed more sensitive. This “special category data” includes information revealing racial or ethnic origin, political opinions, religious or philosophical beliefs, trade union membership, genetic data, biometric data for identification purposes, and data concerning health.
Data Protection Principles
The act was built on core principles like adherence to the law, fairness, transparency, limitations on purposes, minimizing data, ensuring accuracy, restricting storage, maintaining integrity, and preserving confidentiality. Adhering to these principles ensures the lawful and ethical handling of personal data.
Rights Under the IDPC
Individuals in Italy possess various rights under the Data Protection Code, including access, rectification, erase, restrict processing, object to processing, and data portability. Individuals gain authority over their personal information through these rights, allowing them to assert control over how their data is handled.
Who Needs to Comply with the IDPC?
The Italian Data Protection Code applies broadly and transcends specific industries. Any organization that processes the personal data of Italian residents must comply with the Code, regardless of industry or location. Here’s a breakdown of which entities are required to comply with the act:
- Companies: This includes all for-profit businesses, large or small.
- Non-Profit Organizations: Charities, NGOs, and other non-profits must comply if they handle Italian resident data.
- Government Agencies: Public sector entities also need to adhere to the Code when processing the personal information of Italian citizens.
Noncompliance Fines
The Italian Data Protection Code imposes significant fines for non-compliance. The maximum fine under the Code reaches €3 million. The Code utilizes a two-tiered system for determining fines. This means the specific penalty amount depends on the severity of the violation. Here’s a breakdown of the structure:
- Lower Tier: For less severe infringements, fines can range from a warning to a maximum of €250,000.
- Higher Tier: More severe violations, such as unlawful processing of sensitive data or failure to implement appropriate security measures, can incur a maximum fine of €3 million.
- GDPR Interaction: “It’s vital to note that the Italian Data Protection Code complements the GDPR, which imposes hefty fines for violations, up to €20 million or 4% of global annual turnover.
Compliance Authority
The Italian Data Protection Authority (Garante per la protezione dei dati personali) is responsible for enforcing the Code. They can investigate complaints, issue fines, and order corrective actions.
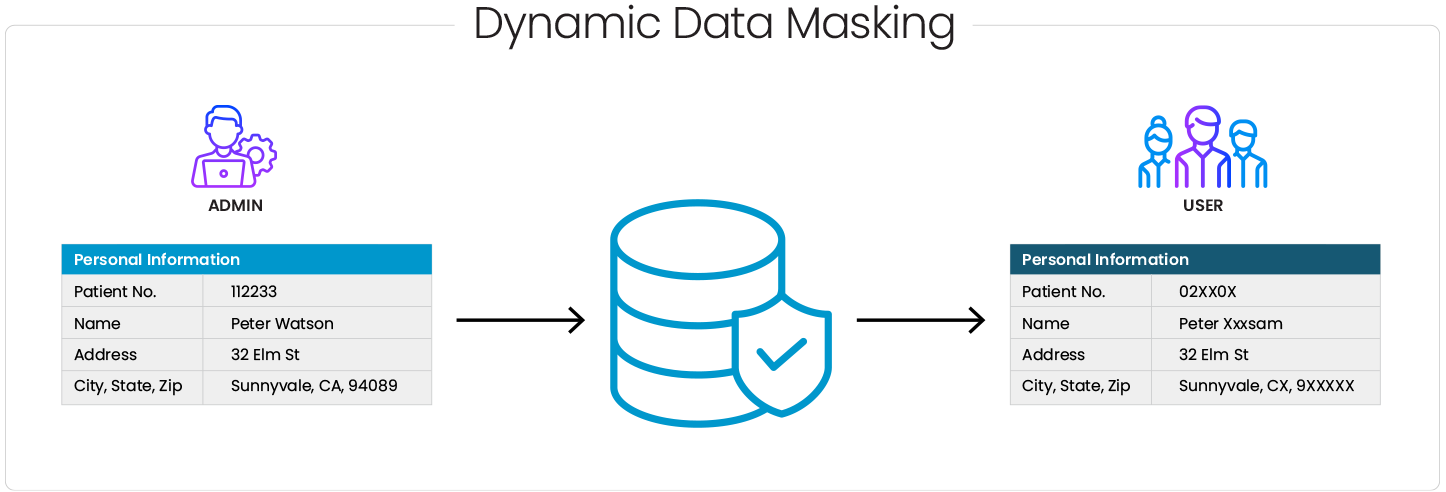
In conclusion, understanding and adhering to the Italian Data Protection Code is essential for organizations operating within Italy’s jurisdiction to ensure personal data’s lawful and ethical handling. Conducting regular audits, providing ongoing staff training on data protection practices, and implementing robust data governance practices, like data masking, can significantly aid compliance efforts.
FAQ
How does the Italian Data Protection Code align with the GDPR?
The Italian Data Protection Code aligns closely with the GDPR, supplementing its provisions to ensure comprehensive data protection within Italy’s legal framework. Both regulations share similar principles and rights, providing a unified approach to safeguarding personal data.
How does the Italian Data Protection Code handle data transfers outside the EU?
The Italian Data Protection Code permits data transfers to countries outside the EU only if adequate safeguards exist, such as standard contractual clauses, binding corporate rules, or the recipient country’s adequacy status.
Are there any exemptions for small businesses under the Italian Data Protection Code?
While the Code applies to all organizations processing personal data, certain obligations may be tailored to a business’s size and complexity, ensuring proportionate compliance efforts.